TLoL: Human level in League of Legends using Deep Learning (Part 4 - Exploring the Literature)
Table of Contents
- Table of Contents
- Introduction
- Exploring the Literature
- Supervised Learning Achieves Human-Level Performance in MOBA Games: A Case Study of Honor of Kings
- Summary
- References
Introduction
This post reviews successful MOBA playing AI agents within the literature, what they done well, what could have done better and then concludes with what can be used in creating a human-level League of Legends AI.
Reviewing current literature is useful as it allows us to utilise a variety of methods, with detailed explanations of each method, for creating MOBA playing AI systems. This post won’t explore the OpenAI Five (Dota 2), AlphaStar (Starcraft 2), MuZero (Deepmind general game playing AI) or other related papers. That will be explored in more detail later on if it’s relevant to the project.
Exploring the Literature
Honor of Kings
Honor of Kings is essentially a League of Legends mobile rip-off created by Tencent when Riot Games didn’t think it was feasable to create a mobile version of League. Obviously they changed their minds later with Wild Rift. Honor of Kings is the most widely played MOBA game in the world with a very large player base in China. The game is estimated to have 119 million monthly active players in March 2019.
Honor of Kings is relevant to this literature review as the majority of the research concerning MOBAs, aside from OpenAI Five, comes from Tencent’s AI Lab. To summarise, Tencent have copied and improved upon the techniques which Open AI originally used in their Open AI Five system. However, they have also explored other techniques such as using purely supervised learning approaches on human expert data, hierarchical learning approaches and others which are useful for building a human-level League of Legends AI.
The rest of this article will cover key papers which have covered creating human level MOBA playing AI systems for Honor of Kings.
Supervised Learning Achieves Human-Level Performance in MOBA Games: A Case Study of Honor of Kings
Overview
This paper is by far the most relevant to this project. The key contribution of this paper is to use a supervised learning approach to classify observations based on what action an expert performed next in the same situation. The system which is introduced by the paper is known as JueWu-SL (which means “Insight and Intelligence” in Chinese and SL refers to supervised learning).
The key principle behind the approach is that decision making within MOBA games can be split into two main parts at any timestep, 1) Where to go on the map for a single hero, this is known as macro, and 2) what to do when your hero reaches the location, this is known as micro.
There are multiple motivations for using a supervised learning approach to create a MOBA playing AI. For starters, a policy network can be pre-trained using a supervised learning approach which can then be used to train the agent further using reinforcement learning. This was crucial to the success of AlphaStar, whereby the authors said that using a purely RL approach would have taken the system too long to converge on the fundamentals of the game, such as how to utilise units to perform basic actions, basic macro and other fundamental skills. Further motivation comes from how a pure supervised learning approach was able to produce a human level Super Smash Bro’s AI system.
The paper suggests modeling the problem of which action the agent should take next as a hierarchical multi-class classification problem. This is done by modelling each observation as a multi-view intent label to model the players macro strategy and hierarchical action labels for modeling micromanagement.
Main Contributions
The main contributions of the paper, and the reason why it’s so useful to this project, are the following two reasons:
- Supervised learning method which can apply to any MOBA game which allows efficient incorporation of expert knowledge. Scene-based sampling method to divide whole MOBA gameplay into easily tuned game snippets.
- Supervised learning method performs comparatively against High King players (roughly Grandmaster or Challenger in League of Legends).
Method
Overview
The paper uses two main types of features throughout the system. The first type of feature which the paper uses is a vector feature. Vector features are used to store game state features such as number of kills, creep score, XP, and other scalar features at each timestep. The other type of feature which is used are image-like features which are used for representing map like images. The map like images are 2D images from the game such as the minimap, nearby skillshots, and other spatial features.
The paper also uses labels in different ways.
The first type of label are “intent labels” which are used to infer what human expert players were attempting to do within the replay files. These intent labels are multi-viewed and there are separate intent labels for global and local intents. These labels are only used as an auxiliary signal during training to improve performance.
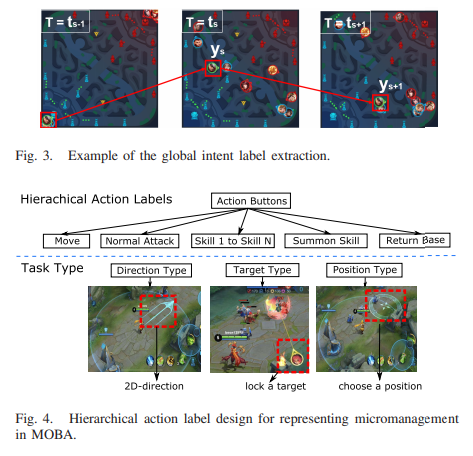
The next type of label are action labels which are arranged in a hierarchical multiclass structure which contains two parts.
-
Action to take at a high level
This is the overall action to take at a high level. Examples would include, movement action, attack action, spell action, and other general high level actions. This is the level 1 prediction.
-
Discretized action parameters
The next level is the level 2 prediction which are the parameters for the level 1 action prediction. This changes dependent on the level 1 action prediction. For example, if the level 1 prediction is movement, then the level 2 prediction are the x and y offset parameters. If the action was an auto-attack instead, then the parameter would be the unit to attack.
The action labels are the main outputs for the model and the intent label is not used as an output during inference.
Multiview Intents for Macro-strategy
The paper describes ground-truth regions which are regions where players conduct their next attack.
However, one issue is that the occasional attacking behaviour in a given spot might not be the goal of the player, such as encountering an enemy while moving somewhere.
Therefore, only regions with continuous attacking behaviours are considered as being distinct enough to categorise a scene. Multi-view intent labels, including global intent and local intent, are used to model macro-strategy and are trained as an auxiliary task during training. The signal derived from this part of the network is still used during inference, but it isn’t an output of the model. However, as the projection from this part of the system can still be maintained during inference, it could be a useful way of determining what the model is “thinking” when it is playing against other bots or human players.
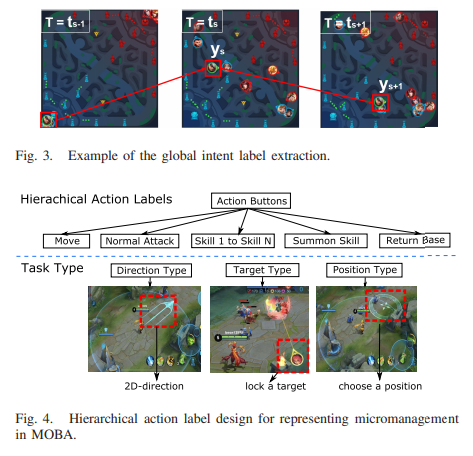
The first level of intent labels are global intent labels. The global intent labels encode the global intent, which is the next target or region where players may attack creeps to gain gold, attack turrets for experience and others.
The global intent label is defined by dividing the map into course-grained N x N regions (for Honor of Kings, N = 24 so 576 intent classes are defined). Therefore, the global intent label is the numbered region on the map where the next seris of attacks happen. For instance, if the next global intent region is at position 1 x 1, that would be equal to Y * N + X := 1 * 24 + 1 = 26 so the label would be 26 out of 576.
.png)
The image above shows an example of a League of Legends game represented as a scatter plot. Each point on the map represents a location where a player has been at some point in the game (with the plots being color coded for 1 of the 10 champions in the game). The cells represent a 32 x 32 grid which compromise the global intent labels, of which there are 1,024.
The next level of intent labels are local intent labels. The local intent label is short term planning in local combat and other scenes (e.g., hiding in a bush, retreating to a turret, waiting for target heroes before attacking a target). A local intent region is defined by dividing a local map region into fine-grained M x M regions (for Honor of Kings, M = 12), where each local region edge is roughly the size of the edge of a heroes length (e.g. if the edge of a heroes collision box is 100 units, then a local regions size would be 100x100).
Example of global intent label and micro-decision making.
Multimodal Features
The JueWu-SL model uses multimodal features throughout the model. As described before, it uses vector features and image features. The models vector features are made of observable hero attributes and information relating to the state of the game. Examples include:
-
Hero attributes
Examples of hero attributes include: current HP, previous HP (HP in the last timestep), ability cooldowns, damage attributes, armor, magic resistance, level, experience, current position on the map, position in the last time step and others.
-
Game states
Examples here include: team kill difference, gold difference, experience difference, game time, turret difference, epic monsters killed (League equivalent of baron and dragon) and others.
Data Preprocessing
One major contribution of the paper is how it divides events which happen within expert replays into scenes. The paper also uses a host of other techniques to get the most out of expert replays, and fortunately for us, these techniques are generic across MOBA games, and RTS games in general.
Scene Identification
Scene identification classifies a scene based on the most prominent actions which a player was performing within a certain timeframe. Unfortunately, the paper is vague on how this process is actually performed but can be inferred with enough effort. The main scenes which the paper identifies as being relevant, to Honor of Kings at least, are listed below:
- Push-turret: Attack enemy turret
- Combat: Find an enemy hero and fight them or prepare to fight them
- Lane-farm: Kill minions to get gold and experience
- Jungle-farm: Kill jungle camps to gain gold and experience
- Return: Go back before dying / to defend the base
- Navigation: Go to another region for macro-strategy intents
Data Tuning Under Each Scene
Depending on the scene, certain types of action intents should occur more (e.g. during Navigation, moving action intent should occur the most, whereas when attacking lane farm, attacking action intent should occur more).
Certain situations involve more than one scene. For example Push-turret can be Combat
and Push-turret scenes combined. Priority under that situation is the order of scenes
under the scene identification section above.
Data Tuning Across Scenes
After segmenting individual frames into scenes, the data is imbalanced across scenes
as certain scenes occur more often than others. This is because things like Push-turret
occur less than Combat.
Distributions of scenes are different in terms of hero roles. For example, the
support role is going to use movement mostly to detect opponents and support teammates, therefore,
most of its game scenes will fall under Navigation (and this is what the authors of
the paper found during exploration). However, the performance of all scenes are equally
important as everything that happens in a game is important to winning the game overall.
To remedy this, the paper uniformly balances scene data by downsampling to enable the
AI to be adequately trained in every scene. What downsampling means in this context is that,
some scenes for certain champions may be trained on more than what would be for other
champions. For instance, you may train agents trained to play a support champion with
more Navigation scenes. However, if you was training an agent to play a carry role champion
(e.g. attack damage carry), then you would try it on disproportionately more Combat scenes.
The downsampling ratio is tuned hero-by-hero.
An important thing to note here is that, scenes are only segmented during training.
During inference, the only thing the model is provided with is an observation at timestep
t with the same information a human would be provided with. There is no difference in
training between scenes.
Move Sample Enhancement
Movement samples are taken by taking the different between a current and future frame,
i.e., after N frames, depending on whether the hero is in combat. In a Combat scene,
N is set as a fine-grained step as every move is important during a fight. In other scenes,
it can be a coarse-grained step, since the player usually executes meaningless moves.
In Honor of Kings, N = 5 (0.33 seconds) during Combat, and N = 15 (1 second) for non-combat
scenes. To put this into concrete terms, the below image shows the movement vectors within
League of Legends at the start of the game when players are leaving the their spawn location.
 (red-side-spawn).png)
The image above shows the movement vectors from the start of a League of Legends game, zoomed into the red side spawn location. As you can see from the image above, the vectors have a high magnitude as players are given the “home-base” buff at the start of the game which is a temporary increase in movement speed at the start of the game. This allows players to move to their respective locations faster to get the game started quickly. Each arrow (or movement vector) is the difference in position for a single champion every 1/8 of a second (the recordings are taken 8 times a second). That is why you can see the arrows growing larger, as the champions are running out of base, they are accelerating so they are covering more distance per timestep.
Attack Sample Normalization
One interesting issue the authors of the paper encountered was to do with Combat scene
sampling. One important decision agents need to make
when they’re in game, is which targets to select during Combat and Push-Turret scenes.
In the raw dataset, examples of target selection for attacking are imbalanced between
low-damage high-health (LDHH) heroes and high-damage low-health (HDLH) heroes. There are
far more examples of attacking a LDHH hero than attacking a HDLH hero due to players
having relatively high HP in most situations. Without downsampling, the model learns to
prefer attacking LDHH
heroes. However, the priority target in Combat scenes is normally the HDLH hero, which
is the key to winning that local teamfight. The paper rectifies this issue by proposing a
hero-attack sampling method, termed attack sample normalization, which samples the same
number of examples for one whole attack process for all heroes (i.e. same number of
examples of LDHH and HDLH attack priorities so the agents are provided with a balanced
number of both situations rather than heavily learning to do one over another).
Training
Dataset
The dataset for the system comes from the top 1% of players in Honor of Kings. In League of Legends, this would be equivalent to around Diamond III or above (as of 04/09/2021 in EUW). Each sample from the dataset contains features, labels, label weights, frame numbers and so on. The overall performance score of each player after the game and and a real-time score of each player during the game based on the player’s performance is stored.
An interesting thing to note here, the paper doesn’t describe how this process is performed. This is a trend I have noticed in machine learning papers in general, but especially from some Chinese research papers where they can be suprisingly lacking in detail for crucial details like this. The method used to determine how a player is performing in the game may have an important impact on training the system, especially for a supervised learning system.
Regardless, a large number of the retrieved games are filtered where games which are poorly performed by players are filtered from the dataset. This is based on the performance score calculated in the previous step, where individual performances which are below the top 10% of performances are disregarded. These samples are for an individual hero as the models are trained to play individual heroes.
Afterwards, the data is preprocessed, shuffled and stored in the HDF5 format, which is a common format for storing large files for big data problems.
After pre-processing the replays, the paper describes how only around 1 out of 20 frames are kept from the original dataset. Around 100 million samples from 120,000 games are extracted for one hero in their experiments.
Each dataset per hero is randomly split into two subsets: 1) a training set of around 90 million samples, 2) test set of about 10 million samples.
Model Setup
The model uses vector features which contain 2,334 elements (2,180 for ten heroes, 154 for the players hero). For the local view (refer to the earlier section on local intent), the edge length is set to 30,000, 1000 edge length for a hero and a 31x31 grid (of 1000,1000 sized local regions). The global map is split into 24x24 grids (with an edge length of 113,000 which is the length of the map). The global image-like feature is of shape (56, 24, 24) which results in 56 channels.
One model is trained for each hero. For each hero, 16 Nvidia P40s (roughly equivalent to an Nvidia GTX 1080 Ti in TFLOPS performance), are used to train a hero for around 36 hours of wall clock time. The Adam optimiser is used to train the network with an initial learning rate set to 0.0001 (10e-5) and the batch size is set to 256.
For the purpose of building the human-level League AI, this shows that the hardware requirements of using a purely supervised learning approach is far more viable than using a comparable distributed, online reinforcement learning approach similar to the one used by AlphaStar or OpenAI Five which used 100,000s of CPUs and 100s of GPUs for months at a time. In the case of OpenAI Five, the training cost per day was estimated to be $25,000 dollars a day which is a very large amount of money. However, what this paper has showed is that it is not necessary to spend this amount of money on training an agent if your goal is only to achieve human level or super human level performance if you use expert data. The final JueWu-SL system managed to beat the Honor of Kings equivalent of Challenger level players using a purely supervised learning approach.
For our system, instead of using 16 Nvidia P40s, we can use Google TPUs which have a high performance to cost ratio compared to other solutions.
Summary
This shows that intelligently choosing your dataset can massively improve the efficiency of your learning process. Compare this to the bootstrap training used by AlphaStar, which requried 971,000 replays to achieve a top 16% performance in Starcraft 2. Whereas this system used 120,000 replays per hero and achieved superhuman performance. Although Honor of Kings and Starcraft 2 are not directly comparable, this is relevant to this project as Honor of Kings and League of Legends are highly comparable games. This would suggest, at least in theory, that training a League of Legends agent to a human level would only require 100,000s of replays to achieve a super human level performance, and that, if the goal is only to achieve human-level performance, it may take far less games than that.
Summary
In summary, what we’ve found from the literature is that it’s possible to achieve, not only human-level performance in MOBAs, but superhuman level performance if you carefully calibrate your dataset, model and have enough data (on the order of 100,000s of replays). We’ve also seen that a more modest, 16 Nvidia P40 GPUs can successfully train a single superhuman level MOBA playing AI system, within 36 hours.
However, it is important to take results from the literature with a grain of salt as researchers, especially within the reinforcement learning community, can often find it difficult to reproduce results from papers due to the previously mentioned issue of the lack of detail in many machine learning papers.
That being said, if the results are truly reproducible, then the equivalent of 16 Nvidia P40 GPUs would be a Google TPUv2 which is a second generation TPU ASIC device offered by Google on their Google Cloud Platform (GCP). The peak processing power of a TPUv2 is 180 TFlops (teraflops/second) which is theoretically more powerful than 16 Nvidia P40 GPUs.
Fortunately for the supervised learning approach to creating a MOBA playing AI, it is possible to have a purely batched approach to learning. That means it is possible to take advantage of cheaper, interruptible hardware on the cloud which is around 20% of the full price of hardware renting. For instance, on GCP, renting a TPUv2 (preemptible) per hour costs $1.35 dollars per hour (as of 04/09/2021). So if we assume that training our system will take a similar amount of time (bearing in mind this is for training on 120,000 replays which for us will be just over 1TB of replay data which is massive), it will cost $1.35 * 36 = $48.6 for a full training run and assuming no issues crop up during training.
However, there are solutions around even this issue. For instance, Kaggle offers a third generation TPU, or Google TPUv3, which has a mindblogging peak performance of 420 TFlops, for free for 9 hours. Considering that the TPUv3 has ~2.3x higher performance, it might be reasonable to assume that a full training run can be reduced from 36 hours to 16 hours. However at this stage, this is full speculation, and as with many aspects of machine learning, these numbers could be completely out of scope.
The summary of this post is that, there is a lot to be optimistic about, but we should be cautiously optimistic as a lot of assumptions made here are currently untested for this project and come from papers released with a relatively low amount of detail concerning the implementation of a lot of the details of these systems.