TLoL: Human level in League of Legends using Deep Learning (Part 3 - Initial Ideas)
Table of Contents
- Table of Contents
- Introduction
- Initial Ideas
- Summary
- References
Introduction
This post explores how to acquire replay data in League of Legends, the League of Legends rofl replay format, and how to extract granular information from a replay file using a method which alleviates the encryption of the replay files in a way which is robust from patch to patch, as the game is updated once every two weeks.
Initial Ideas
Acquiring Data
The previous posts highlighted the main difficulties with creating human-level game playing AIs. The central issue with all of these systems was having enough high quality data to learn from. It is highly recommended to read part 1 and part 2 of this series for better context going forward if you are not already familiar with the history of League of Legends AI systems or game playing AI systems.
For instance, recent AI systems which were built to play board games, could directly simulate the games as the rules governing board games such as Chess and Go are very simple to implement on CPUs and those board games only contain a limited number of overall moves per game. An average Chess game only contains 40 moves per game whereas an average game of Go contains roughly 200 moves per game. On the other hand, MOBAs such as Dota 2, or League of Legends, require a player to make 1000s of decisions over the course of a game. For a more thorough examination of why MOBAs are a complicated problem for AI, refer to “MOBA: A New Arena for Game AI”.
As highlighted in previous posts, training a deep learning based AI agent for League of Legends requires data, and potentially, quite a lot of data. There are two main ways of acquiring data for this task:
Data Acquisition Methods
-
Simulate many games to generate data
This approach would require an API for League of Legends which would allow a developer to automatically provision games, the players within the game, customise variables within the game and to integrate that into a more general machine learning framework. Not only would this require the support of Riot Games, as such an API doesn’t currently exist (as of 03/09/2021), it would also be a large and complicated undergoing even if the API did exist. This is highlighted as a relevant issue by OpenAI within their blog posts, where they mention that a major issue, especially early on for their efforts, was managing the integration of the Dota Bot Scripting API in conjunction with their own software.
-
Use human replays
On the other hand, it is also possible to train an AI system using human replays. The human replays serve as expert examples of how to play the game.
A machine learning agent would then be trained to either, learn how human experts responded in similar situations and training the bot to copy the responses. This would be done using a supervised learning approach where the agent is provided an equivalent observation which humans were provided in-game, and is then trained to predict what action the human would have taken in the same situation.
An alternative approach would be to use an offline reinforcement learning approach whereby an agent would also be provided with an in-game observation, the same as above. However, the agent would also be provided with a reward so the agent is provided with trajectories (state, action, reward), or (s, a, r) tuples (where the state is the observation). This constrasts with the supervised learning approach where the agent is only provided with the observation and the action, and is only trained to repeat the action. The benefit of using offline reinforcement learning, or in this case offline inverse reinforcement learning (offline IRL), is that the agent can learn to infer what was good about what the human experts did, and then copy that. But it is also possible for the agents to learn how to perform better than the examples provided as they are learning trajectories of responses, rather than merely copying them.
Deciding on a Data Acquisition Method
Out of the two data acquisition methods listed above, the most feasible one is to use human replay data. The main reasons are that the reason that previous game playing AI approaches have used massively scaled up, distributed and parallel simulations of the target games are that these projects were undertaken by large AI research organisations which had research goals in mind.
For instance, the OpenAI Five system created by OpenAI was created to prove that the Proximal Policy Optimization (PPO) algorithm could learn to play a popular, complicated esports game which would garner a lot of attention if they could achieve that goal, and also for many of the reasons mentioned within the “MOBA: A New Arena for Game AI” paper. OpenAI done this with the intention of applying the same algorithm to more complex and real-world focused tasks as well and they were successful.
The PPO algorithm has been used everywhere from improving the dexterity of robot hand manipulation, to improving the locomotion of quadrupedal robots and even to my own work of training a basic League of Legends agent to avoid another agent.
Deepmind also had similar reasons for using a similar system when creating AlphaStar, and also because, in theory and in practice, reinforcement learning systems can achieve superhuman performance as they learn for themselves how to play games.
For the purpose of this project, I do not have the budget nor the resources or the support of Riot Games to attempt such a massive undertaking. So for these reasons, I have decided on using human replay data for the purposes of cost, the fact that human replay data alone is likely sufficient for the task, the scale required to implement a massive reinforcement learning pipeline and simplicity.
League of Legends Replays
League of Legends replays are stored as files with a ROFL (yes, really lol) file
format extension. The files are prepended with the region the game was played
and the middle is the game id. A typical league of legends replay file looks
something like EUW1-5237530168.rofl. The replay file is split into two main important parts,
with the first part containing metadata about the game in a JSON format, and the second
and main part of the file are the actual low level contents of the game themselves,
such as the position and stats of every game object at a point in time, the actions
which players took at each timestep, and other low level details.
This second part of the replay file is what is interesting from a machine learning perspective. Riot Games doesn’t provide official documentation as to how this part of the file works, but unofficial attempts to understand the format overtime shed some light on the format. The following two sections are taken from unofficial sources from around the internet, which have attempted to decipher the ROFL file format.
Replay Metadata
The first relevant part of the replay file is a large JSON structure which contains metadata about the replay. It contains many high level aggregated features such as damage dealt per champion, champions and player IDs within the game, number of objectives taken, gold acquired over time, xp (experience) acquired over time and many other aggregated statistics.
Although each replay file contains a lot of high level, and potentially quite useful information, the data isn’t granular enough for a game playing AI system to learn from. The problem with the data is that the temporal resolution is too low. Each data point within the metadata is recorded at most, every 60 seconds. This isn’t high resolution enough for an agent to learn how to make decisions in real-time.
This means that we need to investigate how to extract data from the second part of the replay file.
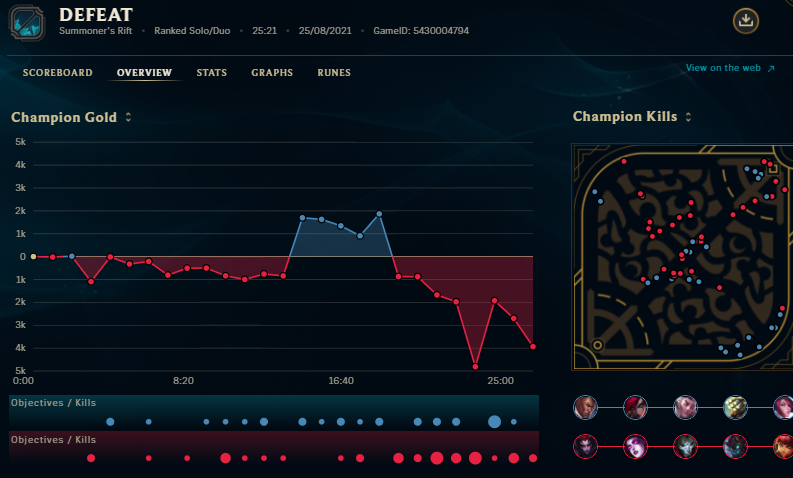
The image above is an example of the data contained within the metadata of a rofl replay file.
General Binary Format
The second part of the replay file is split into keyframes and chunks. A keyframe contains a set of packets which will recreate a League of Legends game state at the time specified within the keyframe. A chunk contains the server to client (S2C) packets of the game during the timespan of a single chunk. Each keyframe and chunk is a sequence of blocks with each block starting with a marker byte which determines its structure. A block encapsulates a game packet.
The most important issue about this section of the data, is that it uses a custom encryption scheme which is embedded inside of the League of Legends client. From patch 4.20 onwards, Riot Games started encrypting their game packets to prevent tampering and cheating. As a consequence of this, this means the game packets stored inside of rofl replay files are also encrypted. The encryption scheme used to encrypt the game packets is stored locally within the game *.exe client itself. This can be seen because it’s possible to view League of Legends replays within the client when offline, presumably this is to simplify the replay system and because it reduces the traffic and processing power which Riot Games needs to dedicate to this service as they only need to providea service to download the replay files.
However, if someone was to create a method of decrypting rofl replay files, it would make it very easy to process these replay files as the raw packet data would be available for analysis. For the most comprehensive attempt to date for understanding the League of Legends packet files, refer to the LeaguePackets project which is a part of the larger LeagueSandbox project. The LeagueSandbox project is an attempt to create an open-source, reverse-engineered version of the League of Legends game server from patch 4.20, which was the last League of Legends version to use unencrypted packets.
The main issue with the encryption scheme is that it changes every patch, for example, replays for client version 11.15 cannot be read using client version 11.16 because the encryption scheme changes between patches. Although it is possible to reverse-engineer the method used to encrypt the replays every patch, this would require performing this process every patch. The issue with this is that League of Legends is patched very frequently compared to most games. The average patch cycle for League of Legends is 2 weeks. This means that whatever method was used to decrypt replay files for a single patch, would need to be adapted every two weeks and on top of that, if the encryption scheme was to change significantly between two patches, it may take even longer to implement.
Downloading Replay Files
Before processing any files, there must also be a system in place to automatically download a large number of replay files. The main way of downloading replay files is to sign-in to the game client, and manually locate files (which must be played on the same patch) within the target players match history, and click on the download button. Downloading the number of replay files required to train a machine learning system in this way would be very time consuming and cumbersome. Also, the League client only displays the last 20 matches a player played in their match history. This means even if a player has played more than 20 games during that patch we would not be able to download all of their replay files for that patch.
Fortunately when Riot Games updated the League of Legends client in 2017 with their updated League Client Update (LCU), the new client also included a new API to directly interface with the client. This allows us to automatically download a large number of replay files and bypass the 20 game match history limit.
Replay File Calcuations
From my own testing, there is a limit to how many games can be downloaded from one account at once. When I tried to download 1000s of games at once, I was throttled to around 1000 games an hour. The average rofl replay file within that dataset (which consisted of around 3,700 NA rofl replay files during patch 11.10), was 13MB. That means 1,000 replays take up around 13GB of data. I used a 40MB/sec (or 350Mbit/s) download connection so I certainly had more bandwidth than 13GB/hr. This means that Riot intentionally throttles the download of rofl files from their servers. More on this later on.
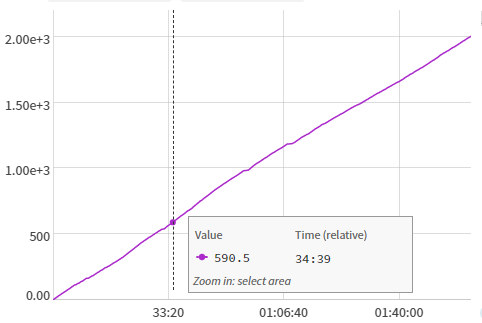
The graph above shows how many replays were successfully downloaded over a 2 hour download stretch.
With that in mind, if it takes 100,000s of replays to produce a competitive human level AI, the storage required for the replay files alone would be 13MB * 100,000 ~= 1.3TB of storage. That leaves two important considerations going forward, download throughput and storage.
Download throughput is the main issue as downloading just 100,000 replays would take 1,000 hours, or ~42 days, with that throughput. One obvious way to alleviate this issue would be to distribute the downloading of replay files across multiple virtual machines which are logged into different accounts across different IP addresses. This could be relatively easily implemented using cloud services.
The other issue is the storage of all of these files. I personally don’t have the storage space to store 1.3TB worth of replay files every patch, so let’s look to the cloud. On the Google Cloud Platform (GCP), the cost of standard storage per GB per month is $0.02 (as of 03/09/2021), which means that storing just 100,000 replays would cost 1,300GB * $0.02 which is $26 dollars a month. Standard storage would only be required when analysing replay files or their data processed form. When the system has matured and we only need to access the data a few times a month we can use nearline storage which costs half as much which is $13 dollars a month.
Different storage providers may be a better choice depending on how the project goes, however, I would like to take advantage of Google BigQuery as it provides a very powerful tool to query TBs worth of data very quickly.
Replay Downloading Automation
Using the cloud also makes it easier to provision multiple public IP addresses quickly and automatically rather than manually setting up a manual system of different IP addresses.
To create the automatic replay downloader, it would require setting up virtual machines running linux (I ain’t paying for Windows VM, lol). On those linux VMs, you would need to install Wine and League of Legends and automatically log into the VMs with a level 1 account specifically created to download replay files. Fortunately, the LCU API also provides a call which allows someone to automatically log in without using the League client’s UI. This allows the process to be automated without using something potentially unreliable such as PyAutoGUI.
From here, a service could be setup which receives requests to download replay files based on the region and game ID of the replay file to download and dispatches the downloading of the file to a virtual machine or cloud function which handles the actual downloading of the replay file and then stores the replay in cloud storage.
Issues and Solutions Regarding ROFL Replays
At this stage, we have an outline of a system, albeit quite a complicated system, which is able to automatically download a large number of League rofl replays. However, how do we actually go about getting information which is granular enough to train a deep learning agent capable of playing League of Legends to a human-level?
We’ve already explained why it’s not possible to reverse-engineer the rofl file format as the encryption used to protect the data is changed every patch. This means that trying to use the packet data stored within the rofl files directly would result in an “enigma-like” effort where you would be fighting Riot Games encryption every patch, and any major change to their encryption scheme would greatly increase the amount of time required to adjust the system.
The specific issues relating to this are illustrated below, with possible solutions:
Problem: Lack of League of Legends API
With this in mind, the method used to extract low-level, granular data ranging from the position of objects, the actions taken by players, gold and xp earned per second and whatever other granular spatial and temporal data we could possibly want needs to be accessible to create this system.
One interesting solution could be to re-purpose a tool which was originally designed for cheating, to our use. The LViewLoL project which uses a C++ console application to provide access to a live running League game and provides an API to take observations from a game as it’s running and issue actions as the user to the game.
This also has the added benefit of allowing as to load a replay file along with a version of LViewLoL compiled for that League patch version to process the replay file. LViewLol was briefly touched upon within part 1 of this series and will be explored further now.
Solution: LViewLoL Scripting Platform
LViewLoL works by using a system call in Windows called ReadProcessMemory() which allows an unprivileged program to read the memory of another running process. This allows the program to copy memory from specific addresses with minimal overhead. However, how does someone find the addresses of game objects within the League of Legends game engine? The League of Legends game engine is a proprietary game engine developed by Riot Games specifically for League of Legends so it’s not like trying to access memory locations within well known game engines such as Unreal Engine or Unity.
The answer is to use a tool such as IDA Pro, which is a popular tool within the cybersecurity and wider hacking and computer science community. The purpose of the program is to statically or dynamically analyse program binaries. This allows hackers to locate the memory addresses of objects of interest by statically or dynamically reverse-engineering the functionality of programs.
The address offsets for League of Legends data structures are calculated based on the base address of the program (i.e. the virtual memory base location the program expects to be loaded to) and then adding the address offsets to the base address to find the data structures used by the game.
These game objects are then processed by the C++ console application by reading them as the game is running, combining them with static data provided freely by Riot Games to find information such as champion attack ranges, game object IDs and names, and other data required to properly interpret and integrate the raw information from the game engine. The program then provides this information using the C++ boost library’s python interface as an interface for any loaded python scripts, which allows a custom script to be attached which can save observations of game replays as the replays are being played back.
Our replay extracting system can take advantage of the LViewLoL python integration by directly taking advantage of the observations which are provided by the system to build a representation of a League replay which is compatible with our machine learning system. This has the added benefit of already being written in Python, which means that the replay downloading system and the replay extractor system can both be written in Python.
Another benefit of this system is that, as the LViewLoL source code is freely available
and mainly relies on the ReadProcessMemory() system call, it is easy to port to linux as
the ReadProcessMemory() system call can easily be changed with the process_vm_readv().
This also has another unintended benefit, firstly it means that it is easy to port the LViewLoL
system to linux, which is convenient as we can then run the replay extraction process on linux locally or in the cloud. However, the process_vm_readv() system call is also faster
than ReadProcessMemory() as it doesn’t require a context switch, as it was introduced to have
virtually no overhead. This means that, not only can we use linux to extract information from
rofl replays, it might also end up being faster than Windows!
Summary
In summary, the best way of gathering data for this system will be to create an automated system which is able to cycle through League accounts and different IP addresses to alleviate Riot Games rofl download throttling. Then when this automated replay downloading system is implemented, we can use an existing scripting platform on the League Client itself, while running the replay at faster than real-time speed. This allows us to extract information at high spatial and temporal granularity, which is required to train a deep learning agent. This can be done in a distributed fashion, meaning we can gather a lot of data in parallel. This can also all be implemented on Linux by taking advantage of Wine for running League on Linux and adjusting LViewLol to run on Linux.
This leaves us with two main systems which need to be implemented (without consideration for “glue” systems such as servers to distribute requests to cloud instances, cloud inter-operation, or other considerations):
-
Automated Replay Downloader This system would be responsible for dispatching replays matching certain criteria to appropriate services which would then download replays at a rate of 1,000 games an hour. This system would also be responsible for storing the replays in an appropriate storage location using cloud storage (due to the large number of replays, the amount of storage required is in the TB range).
-
Automated Replay Extractor This system would be responsible for replaying the replays using the League of Legends client which corresponds to the replay file, and then running a modified version of the LViewLoL scripting platform for linux at faster than real-time. Then the features can be extracted from the game engine, to be used in a deep learning system.
References
League of Legends Hacking and Scripting
- Scripting: LViewLoL
- Forum: UnknownCheats League of Legends
- Software: HexRays IDA Pro
- C++ Library: Boost
- Linux API: process_vm_readv()
DevOps Automation
Cloud Pricing
LCU API (League Client Update API)
LeagueSandbox (League of Legends v4.20 Server Emulation)
- GitHub: LeaguePackets
- GitHub: LeagueSandbox
- GitHub: League Spec (League of Legends ROFL File Format Information)