TLoL: Human level in League of Legends using Deep Learning (Part 6 - Dataset Generation)
Table of Contents
- Table of Contents
- Introduction
- Overview
- Player and Game Selection
- Replay Downloading
- Replay Scraping
- Dataset Conversion
- Summary
- Resources
Introduction
Following a long hiatus, this section will explain the data generation procedure for the TLoL project and how the datasets generated will be used to create the first agent which can play League of Legends.
Overview
To generate a basic replay dataset for League of Legends, a process to gather replay files and extract useful information from them was required. As has been explained in previous posts, there is no API from Riot to do this so a custom method was required. The League of Legends replay files themselves used an obfuscated and encrypted format which changes with each patch. However, there are scripting tools which rely on scraping game objects from distinct memory locations from the client which are far easier to update from patch to patch. These scripting tools are easier to update from patch to patch because the League of Legends game engine itself doesn’t drastically change from patch to patch. This makes using scripting engines to scrape data from replays loaded into the game client a far more viable approach to extracting data from replays compared to decrypting the League client’s replay decryption method.
Before this, we need to download a sufficient number of replays to extract data from. Fortunately, the League Client Update (LCU) introduced a new API to automatically allow downloads directly from the location where replay files are stored. As it turns out, Riot like many companies now, use Amazon S3 to store their replay files each patch. This means that if you download multiple replay files using this LCU API, you are downloading the files directly from Amazon which means that the download speeds are high.
Data Generation Process
As summarised before, this means we need an end-to-end process for generating our replay dataset. With all of the considerations of the previous posts, this results in the following process:
- Determining which players to scrape replays from
- Determining which games these players have played to download
- Automatically downloading all of these games from Riot’s Amazon S3 replay file store
- Creating a reliable, automated process for extracting information from the replays
- Storing the data from the replays into an intermediate format
- Converting the intermediate format into a format more suitable for storage and processing
Player and Game Selection
Explanation
As explained in part 4 and part 5, it is important to gather data from the best performing players available as that increases the performance of the agent, regardless of how you use the data to train the agent. As such, I simply chose to gather data from the top of the EUW ranked ladder. I would have preferred to use the KR ranked ladder but sadly it is difficult to acquire a KR League of Legends account if you live outside of the region.
As for the game selection, I am using the criteria from part 5 when selecting games,
however, I have decided to change a few things. Firstly, I will be targetting Miss Fortune
instead of Ezreal. The reason for this is that the champion who is most
popular each patch changes based on which champion is currently strong within that patch.
This means that a varying amount of data is available for each champion. Another criteria
which I changed was deciding to scrape games where the game with the desired champion won
the game only. Instead I scraped games where they won and lost and instead used basic
metadata about the performance of that player later on. This means that more replays
are available for the dataset and allows more precise fine tuning of the dataset as whether
a player won or not is a crude estimate of their performance for each game.
Method
Data Source
The data source for this information is the u.gg website which provides a
very simplified API for accessing Riot API information. The u.gg website
is used instead of the Riot API because when the Riot API switched from v4 to v5, they
introduced harsh API limits which rendered it useless for this project. I also avoided
op.gg as the API is out of date and difficult to parse due to it’s age,
this is further explained in part 5.
Process
The process is split into two main parts:
- Gather a list of high elo players from rank 1 down to a specified limit. In practice, the limit was set to the top 36,000 players which roughly comprise the top 1% of players in EUW.
- Gather a list of game IDs which match the criteria we want.
The criteria used was the following:
- Contained either
Miss FortuneorNami(as they were the most popular champions for the target patch11_21). - Games were played on patch
11_21. - Win or loss.
- Contained either
The directory for this process was structured as follows:
- champ_ids.txt (Contained a list to map champion names to their Riot defined IDs)
- replay_scraper.py (Contained the code to gather the game ids)
At first, I tried querying the u.gg and gathered the list of the players one by one, but I quickly found that this was a very slow process. Instead I decided to use multithreading to quicken the process but found that issuing 10s, if not 100s of HTTP requests to a single website per second will quickly get you temporarily banned from using that website. Therefore I introduced a small 0.25s to 0.5s delay between each HTTP request which over 360 HTTP requests (36,000 players / 100 players per page), gave the best balance between increasing the player list generation process and not getting banned.
Afterwards I needed to find games which matched the criteria described above. Fortunately,
u.gg also provides a convenient method within their API to do this.
Now that I had a list of the top 36,000 players summoner names, I could use this to look
through their list of played games during the target patch 11_21 and determine if
each game matched the desired criteria. If it did, it was added to the list of games
which would be downloaded later on. As you can imagine, sending 36,000 queries to
u.gg is also a time consuming process which needed to be sped up
using the same multithreading procedure as above.
The code for both processes combined is provided below:
Below is a real-time log (in seconds) for how long it took me to scrape the summoner names of the top 36,000 players in EUW.
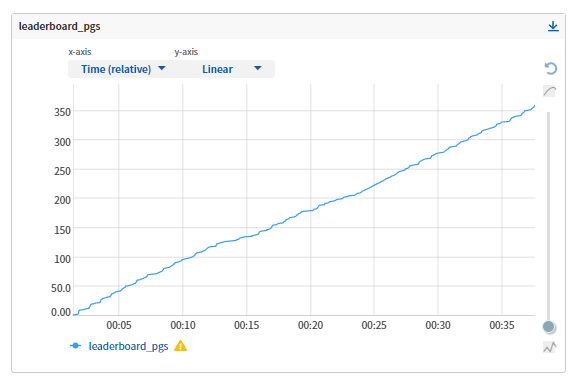
Now that we have a list of game IDs we would like to download from the Amazon S3 replay file store, we need to create a process to actually download the games.
Replay Downloading
Explanation
At this stage, we have a long list of game IDs to download from Riot’s Amazon S3
replay file storage. When I ran the game ID scraping process for Miss Fortune
and Nami, I ended up generating a list of 19,534 and 19,860 games respectively.
However, because I stored the replay files in different directories, this meant that
there could be some games between the two lists which were repeated twice, so I combined
the two lists of game IDs, and removed the duplicates. This reduced the total game
count down from 39,394 to 36,698. This means the final total number of games in our
dataset for Miss Fortune and Nami in patch 11_21 where the player won or lost
contains 36,698 replays. This should be a more than adequate amount of data to create
a human-level League of Legends AI system.
Method
Port and Auth Token
Following this, we actually need to download the games. As mentioned previously, the
League of Legends Client Update (LCU) hosts a server on the localhost which provides
the local user with an API to directly interact with the League of Legends client.
One of the methods it provides is a way to download a replay file just by providing
the game ID. This method only works with replays from the region where the client
is logged into (as League of Legends accounts are tied to specific regions). The replay file must also be on the same
patch as the current patch, as Riot deletes replay files which are from previous patches.
Fortunately, our game ID scraping process only returns game IDs for the patch we specify.
However, to interface with this localhost address, we need to find out which port
the server is being hosted on and also find its credentials so we can connect to it.
The easiest way to do this is to log into the League of Legends client with an account
that matches the server we want to download games from and use a program like
Process Explorer
which allows us to view which command line arguments a process was started with. The reason
we need the command line arguments are so that we can see which port the client is hosting
its API interface on and to get the security token to be able to issue HTTP requests to
the client. The following images demonstate this process:
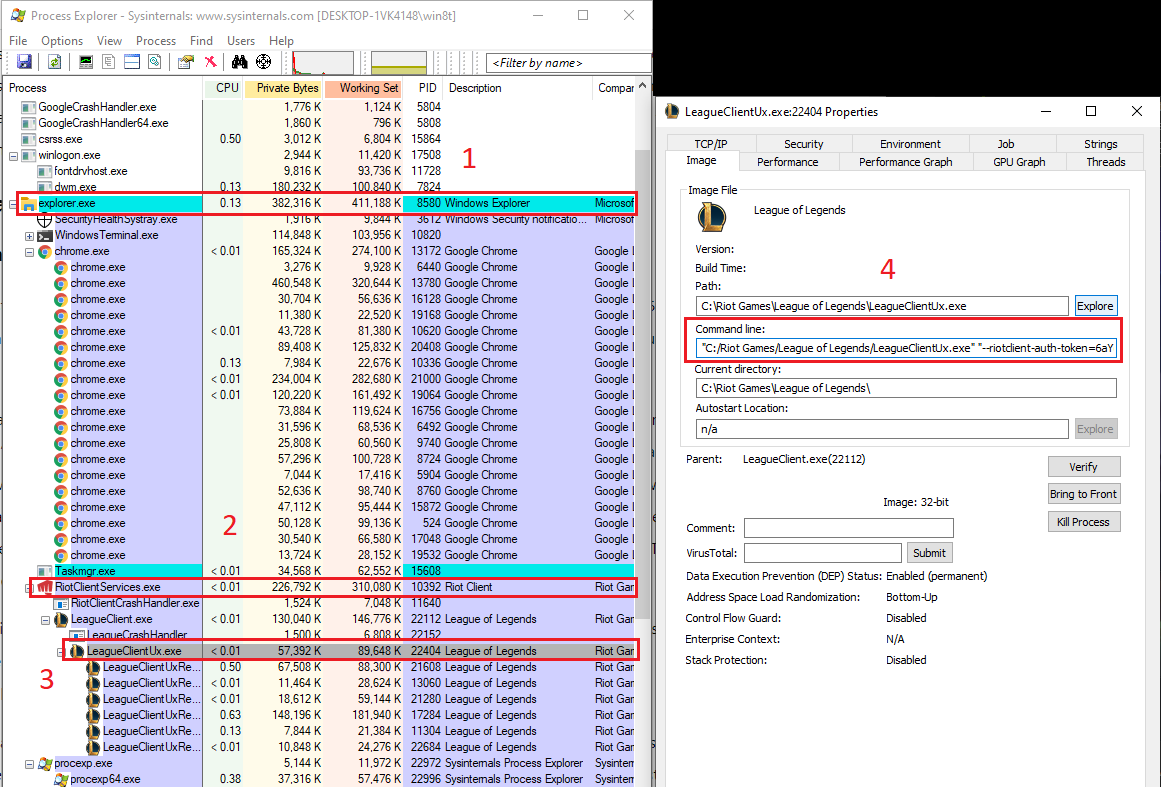
From these command line arguments, you need the --remoting-auth-token and the --app-port
for the next stage. Use the --remoting-auth-token and --app-port with the below code
to download the desired replays. Be aware, if you close the client and then open it later,
the token and port change so you will need to use ProcessExplorer to get these values
again.
Also provided are the real-time logs for 19,681 out of the 36,698 final replay files.
You can roughly double this number to get an idea of how long the full 36,698 game IDs.

Automated Replay Downloads
Now that we know where the server is being hosted and what the token is, we can use
that information along with the required game IDs and begin to download replay files
automatically. For these HTTP requests, I use the same request delay as the u.gg requests as downloads from the Amazon S3 replay file storage take roughly the same
amount of time as the delay which matches the download requests to the amount of time
the downloads take to complete. For me on my internet connection, the downloads peaked at
around 200Mbit/s. For an idea of the peak speed of download replays, refer to the below image
which is a log of the download speed over time when downloading 19,681 out of the
36,698 files.
You can roughly double this number to get an idea of how long the full 36,698
replay files download took.

Replay Scraping
Explanation
At this stage, we have downloaded all of the replay files we want, in my case that is
a whopping 36,698 replay files. The total file size of all of these replays is roughly
500GB, as each replay file on average is about 13.5MB. This should highlight just
how massive reinforcement learning datasets are in general.
Now that we have these files, we actually need to extract useful information from them.
However, during our extraction process we didn’t scrape any metadata about the individual
replay files. Fortunately for us, each *.rofl
file contains a JSON section at the start of the
file which gives fairly detailed information about the game.
This includes it’s patch version, the
summoners who played the game, aggregate statistics about their performance during
the game and which champions the players played. This means that we can generate a small
SQL database with this information and use it to tailor our replay scraping process.
The code used to extract JSON metadata from a replay file is provided below:
Now, this metadata.db SQLite database allows us to query our dataset for useful
information. For instance, we can find out how many replay files we have for each champion.
For instance, we may be interested to know how many Miss Fortune and Nami replay files
we have using this query:
SELECT playerGame.champ, count(playerGame.champ)
FROM playerGame
INNER JOIN games ON playerGame.game_id=games.game_id
GROUP BY champ
ORDER BY count(playerGame.champ) DESC;This query returns the game count for every single champion, however only the top 10 are provided for brevity here:
| Champ | Game Count |
|---|---|
| Nami | 20875 |
| Miss Fortune | 20534 |
| Lucian | 13266 |
| Graves | 7889 |
| Camille | 6552 |
| Viego | 6297 |
| Jhin | 5821 |
| Lux | 5621 |
| LeeSin | 5603 |
| Yone | 5558 |
We can also return games based on their duration. This could be useful in creating a small pilot dataset for us to explore and fine tune ideas before moving on to scraping larger numbers of games. In this case, I decided to find a list of the games where the games ended in an early surrender (first 3.5 minutes of the game) because a player failed to connect to the game. This dataset is useful as it guarantees the game length is low and allows us to determine which features of a game are useful to extract for a machine learning agent. The following SQL query was used to find this list of game IDs:
SELECT game_id
FROM games
WHERE game_mins < 4.0;This returned 191 games, which later became the 191-EarlyFF dataset. Analysis of this
dataset will be provided in a later post.
Method
The process for extracting replay information from games involves using the LViewLoL scripting engine. Although this scripting engine was originally intended to give players an advantage while playing the game, it also has the useful feature of reliably extracting information from the game while the game is running.
The LViewLoL project relies on traversing the tree of game objects which are in the
League of Legends.exe game memory in real-time, and copying information from those
game objects using the ReadProcessMemory() system call. This system call allows processes
to read the memory of other processes without permission elevation. This system call
is used by many scripting engines as it provides a convenient way to read the memory
of other processes with relatively minimal overhead. The LViewLoL project also provides
an interface for Python scripts, using the C++ boost library, to
access these observations and interact with the game.
I initially used the Python interface to gather observations from replays as they were being run but found that the overhead of the Python interface was reducing the efficiency of the replay scraping process because of the overhead between the LViewLoL application (C++) and my python script. Instead, I decided to modify the source code of the LViewLoL application directly and insert my code to save the observations directly into the main part of the code.
Experiments
One of the requirements of the replay scraping process is that we can extract enough
information from the replay files within a reasonable amount of time. This meant that
it was important to determine the maximum throughput of the replay extraction process
using LViewLoL. To do this, I simply printed the in game time while the LViewLoL
application was running with a League replay running in the game client at the same
time. The in game time was printed in the following format: second.milliseconds,
so for example 2.1242.
I then copy and pasted the printed game times from the LViewLoL console
into a text file and used a python script to
put each printed game time into seperate bins based on the second of the game time.
I then found the mean number of game times for each in game second within the list.
After running this process multiple times, I determined the maximum throughput of the replay scraping system, before actually saving any observations, was roughly 128 observations a second. This number is important as it determines what multiplier we can run the replays on when scraping information from the replays.
For example,
if we run the replay’s at the clients maximum 8x replay speed, that means the maximum
number of observations we can scrape per second is
128 maximum observations / 8 replay speed = 16 observations a second. This
leaves us with the following formula:
max_obs / replay_speed = max_obs_sec. However, we can re-arrange this equation
to give us the maximum replay speed which still gives us the required number
of observations per second:
max_replay_speed = max_obs / target_obs_sec.
So for example, if we only want 4 observations / second, then the formula gives us:
max_replay_speed = 128 / 4 which is 32. This is of interest to us because the League
of Legends client contains an interesting feature known as the ReplayAPI. This allows
us to override the default replay speed limits to any number we want. So we can playback
replay files at x32 speed.
Considering the average game within out dataset lasts roughly
26 mins (including games ending in surrender), that means we could scrape a single game
at roughly 26 mins / 32 replay speed which is roughly 49 seconds. This gives our replay
system very high throughput. However, this is just the raw speed, the actual speed
will be slowed down by the following factors:
- Overhead of the game engine loading the *.rofl file from disk and parsing it. In practice, I’ve found this can take up to 15 seconds to load a game on a 7200 RPM HDD, and using an NVMe PCIe SSD only reduces this time down to around 12/13 seconds.
- Overhead of LViewLoL serializing each observation
To serialize each observation within LViewLoL as the game is running, I chose to use JSON to serialize all of the game objects per each observation. Although this is a terrible choice, and something like protobuf3, would be a far better choice (and is used to store Dota2 replays within the OpenDota project), I’ve chosen this for simplicity for now.
This ultimately reduces the maximum number of observations per second from 128 to 64.
This means, using the same formula as before, the maximum replay speed we can now use
is max_replay_speed = 64 / 4 which is 16 and is ultimately the replay speed used
to generate the current TLoL datasets.
This gives us the final formula for calculating how many games can be scraped within
24 hours:
mins_per_day / (mins_per_game / replay_speed + loading_overhead_mins)
which is
1440 / (26 / 16 + 0.25) = 768.
However, for the early datasets, I am only scraping
the first 5 minutes of games as creating an agent which can play the first 5 minutes
of a game alone is hard enough. This results in:
1440 / (5 / 16 + 0.25) = 2,560.
Process
Replay extraction architecture:

SQL query to get best performing 1000 games for a specified champ.
Call this target_games.sql or COUNT CHAMPS.sql or whatever suits you best:
SELECT playerGame.win, games.game_mins, games.game_id, games.game_length
FROM playerGame
INNER JOIN games ON playerGame.game_id=games.game_id
WHERE playerGame.champ = "MissFortune"
GROUP BY playerGame.game_id, playerGame.longest_time_spent_living
ORDER BY playerGame.longest_time_spent_living DESC
LIMIT 1000 OFFSET 0;
Replay extraction multi_scrape.py orchestrator code:
Dataset Conversion
Explanation
Now that we’ve generated a list of JSON files for each one of our replays, this leaves us with one issue, the JSON files take too much storage and are difficult to parse. This means that we need to convert these files into a more efficient data storage which is easier to parse. For this stage, I have decided to use SQLite as it is relatively storage efficient and it allows us to use SQL statements to parse the data, which is sufficient for performing basic data analysis.
Method
To do this, we need to loop through our JSON files, and insert the contents of each JSON file into an SQLite database. The code to do this is provided below:
Summary
At this stage we have done the following:
- Found the top 36,000 players on the EUW Ranked Solo/Duo ladder
- Gathered all of the game IDs from those players that we’re interested in
- Downloaded all of the games found in the previous step
- Extracted observations for a subset of the replays and stored it in JSON format
- Converted the JSON files into SQLite files for easier storage and processing
In the next post, we will actually analyse the data we have gathered, improve the feature selection of the replay process and maybe even start training a basic machine learning model which can play League of Legends once we have gathered more data!